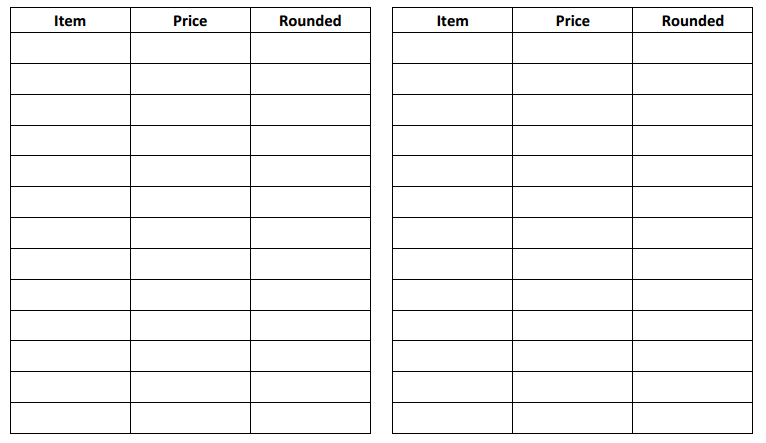
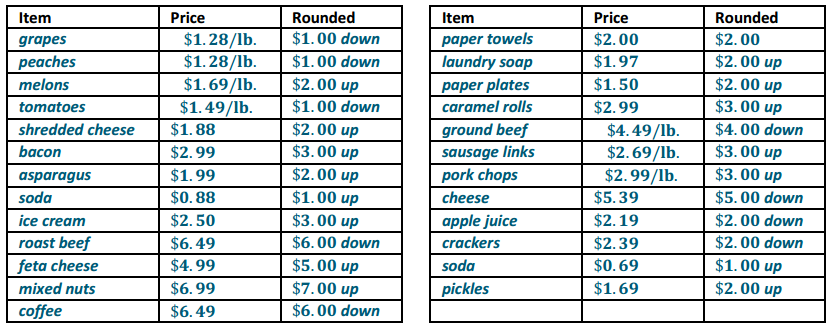
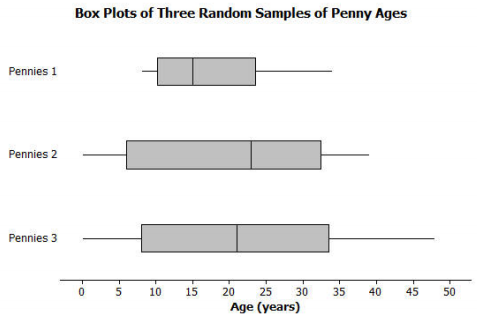
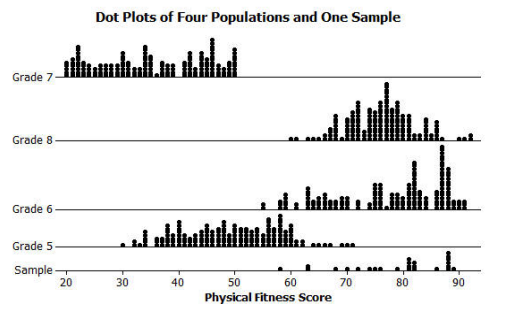
Engage NY Eureka Math 7th Grade Module 5 Lesson 11 Answer Key
Eureka Math Grade 7 Module 5 Lesson 11 Example Answer Key
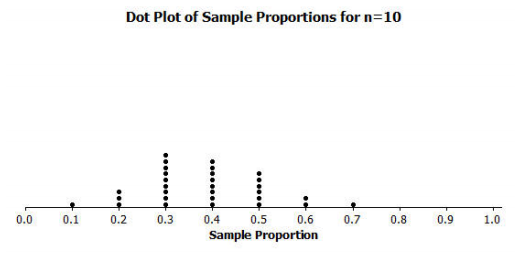
Example 1: Simulation
In the last lesson, we used coins, number cubes, and cards to carry out simulations. Another option is putting identical pieces of paper or colored disks into a container, mixing them thoroughly, and then choosing one.
For example, if a basketball player typically makes five out of eight foul shots, then a colored disk could be used to simulate a foul shot. A green disk could represent a made shot, and a red disk could represent a miss. You could put five green and three red disks in a container, mix them, and then choose one to represent a foul shot. If the color of the disk is green, then the shot is made. If the color of the disk is red, then the shot is missed. This procedure simulates one foul shot.
a. Using colored disks, describe how one at bat could be simulated for a baseball player who has a batting average of 0.300. Note that a batting average of 0.300 means the player gets a hit (on average) three times out of every ten times at bat. Be sure to state clearly what a color represents.
b. Using colored disks, describe how one at bat could be simulated for a player who has a batting average of 0.273. Note that a batting average of 0.273 means that on average, the player gets 273 hits out of 1,000 at bats.
Answer:
Ask students what device they would use to simulate problems in which the probability of winning in a single outcome is \(\frac{5}{8}\). A coin or number cube does not work. A deck of eight cards (with five of the cards designated as winners) would work, but shuffling cards between draws can be time-consuming and difficult for many students. Suggest a new device: colored disks in which five green disks could represent a win and three red disks could represent a miss. Put the eight disks in a bag, shake the bag, and choose a disk. Do this as many times as are needed to comprise a trial, and then do as many trials as needed to carry out the simulation. Students could also create their own spinners with eight sections, with three sections colored one color and five sections a different color, to represent the two different outcomes.
Students work on Example 1 independently. Then, discuss and confirm as a class.
a. Put ten disks in a bag, three of which are green (representing a hit), and seven are red (representing a non-hit).
b. Put 1,000 disks in a bag, 273 green ones (hits) and 727 red ones (non-hits).
Example 2: Using Random Number Tables
Why is using colored disks not practical for the situation described in Example 1(b)? Another way to carry out a simulation is to use a random number table, or a random number generator. In a random number table, the digits 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9 occur equally often in the long run. Pages and pages of random numbers can be found online.
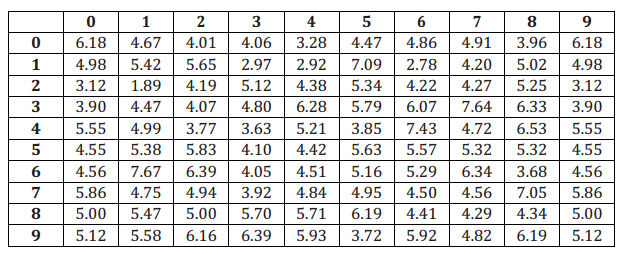
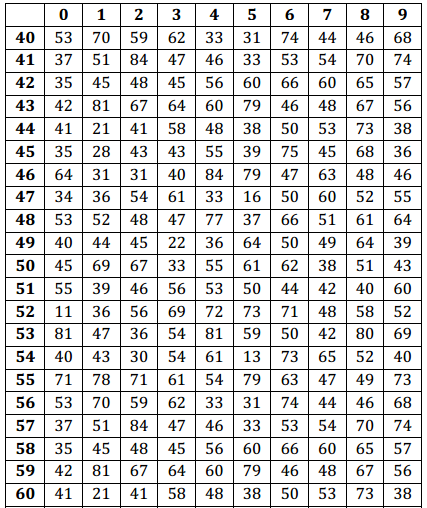
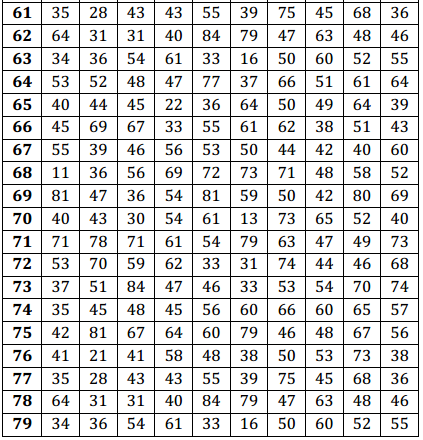
For example, here are three lines of random numbers. The space after every five digits is only for ease of reading. Ignore the spaces when using the table.

To use the random number table to simulate an at bat for the 0.273 hitter in Example 1(b), you could use a three-digit number to represent one at bat. The three-digit numbers 000–272 could represent a hit, and the three-digit numbers 273–999 could represent a non-hit. Using the random numbers above and starting at the beginning of the first line, the first three-digit random number is 252, which is between 000 and 272, so that simulated at bat is a hit. The next three-digit random number is 566, which is a non-hit.
Continuing on the first line of the random numbers above, what would the hit/non-hit outcomes be for the next six at bats? Be sure to state the random number and whether it simulates a hit or non-hit.
Answer:
The numbers are 520 (non-hit), 572 (non-hit), 597 (non-hit), 005 (hit), 621 (non-hit), and 268 (hit).

Example 3: Baseball Player
A batter typically gets to bat four times in a ball game. Consider the 0.273 hitter from the previous example. Use the following steps (and the random numbers shown above) to estimate that player’s probability of getting at least three hits (three or four) in four times at bat.
a. Describe what one trial is for this problem.
b. Describe when a trial is called a success and when it is called a failure.
c. Simulate 12 trials. (Continue to work as a class, or let students work with a partner.)
d. Use the results of the simulation to estimate the probability that a 0.273 hitter gets three or four hits in four times at bat. Compare your estimate with other groups.
Answer:
a. A trial consists of four three-digit numbers. For the first trial, 252, 566, 520, 572 constitute one trial.
b. A success is getting 3 or 4 hits per game; a failure is getting 0, 1, or 2 hits. For the first trial, the hitter got only 1 hit, so it would be a failure.
c. Answers will vary.
d. As a side note, the theoretical probability is calculated by considering the possible outcomes for four at bats that have either 4 hits (HHHH) or 3 hits (HHHM, HHMH, HMHH, and MHHH). The outcome that consists of 4 hits has probability (0.273)4, and each of the 4 outcomes with 3 hits has probability 4 (0.273)3 (0.727). The theoretical probability is approximately 0.0674. (Refer to Lessons 6 and 7 for the rationale for the numerical expressions.)
Example 4: Birth Month
In a group of more than 12 people, is it likely that at least two people, maybe more, will have the same birth month? Why? Try it in your class.
Now, suppose that the same question is asked for a group of only seven people. Are you likely to find some groups of seven people in which there is a match but other groups in which all seven people have different birth months? In the following exercises, you will estimate the probability that at least two people in a group of seven were born in the same month.
Answer:
Note: There is a famous birthday problem that asks, “What is the probability of finding (at least one) birthday match in a group of n people?” The surprising result is that there is a 50/50 chance of finding at least one birthday match in as few as 23 people. Simulating birthdays is a bit time-consuming, so this problem simulates birth months.
Eureka Math Grade 7 Module 5 Lesson 11 Exercise Answer Key
Exercises 1–4
Exercise 1.
What might be a good way to generate outcomes for the birth month problem—using coins, number cubes, cards, spinners, colored disks, or random numbers?
Answer:
Answers will vary; keep in mind that the first thing to do is specify how a birth month for one person is going to be simulated. For example, a dodecahedron is a 12-sided solid. Each of its sides would represent one month.
The following will not work: coins (only two outcomes), number cubes (only six outcomes, and we need 12).
The following devices will work: cards (could label twelve cards January through December), spinners (could make a spinner with twelve equal sectors), colored disks (would need 12 different colors and then remember which color represents which month), 12 disks would work if you could write the name of a month on them, and a random number table (two-digit numbers 01, 02, …, 12 would work, but 00, 13 through 99 would have to be discarded, which could be quite laborious and time-consuming).
Exercise 2.
How would you simulate one trial of seven birth months?
Answer:
Answers will vary; suppose students decide to use disks with the names of the months printed on them. To generate a trial, put the 12 disks in a bag. Then, shake the bag, and choose a disk to represent the first person’s birthday. Then, replace the disk, and do the process six more times. The list of seven birth months generates a trial.
Exercise 3.
How is a success determined for your simulation?
Answer:
A success would be at least one match in the seven.
Exercise 4.
How is the simulated estimate determined for the probability that a least two in a group of seven people were born in the same month?
Answer:
Repeat this n times, count the number of successes, and divide it by n to get the estimated probability of having at least one birth month match in a group of seven people.
Eureka Math Grade 7 Module 5 Lesson 11 Problem Set Answer Key
Question 1.
A model airplane has two engines. It can fly if one engine fails but is in serious trouble if both engines fail. The engines function independently of one another. On any given flight, the probability of a failure is 0.10 for each engine. Design a simulation to estimate the probability that the airplane will be in serious trouble the next time it goes up.
a. How would you simulate the status of an engine?
b. What constitutes a trial for this simulation?
c. What constitutes a success for this simulation?
d. Carry out 50 trials of your simulation, list your results, and calculate an estimate of the probability that the airplane will be in serious trouble the next time it goes up.
Answer:
a. Answers will vary; it is possible to use a random number table. The failure status of an engine can be represented by the digit 0, while digits 1–9 represent an engine in good status.
b. A trial for this problem would be a pair of random digits, one for each engine. The possible equally likely pairings would be 00, 0x, x0, xx (where x stands for any digit 1–9). There are 100 of them. 00 represents both engines failing; 0x represents the left engine failing, but the right engine is good; x0 represents the right engine failing, but the left engine is good; xx represents both engines are in good working order.
c. A success would be both engines failing, which is represented by 00.
d. Answers will vary; divide the number of successes by 50.
Question 2.
In an effort to increase sales, a cereal manufacturer created a really neat toy that has six parts to it. One part is put into each box of cereal. Which part is in a box is not known until the box is opened. You can play with the toy without having all six parts, but it is better to have the complete set. If you are really lucky, you might only need to buy six boxes to get a complete set. But if you are very unlucky, you might need to buy many, many boxes before obtaining all six parts.
a. How would you represent the outcome of purchasing a box of cereal, keeping in mind that there are six different parts? There is one part in each box.
b. If it was stated that a customer would have to buy at least 10 boxes of cereal to collect all six parts, what constitutes a trial in this problem?
c. What constitutes a success in a trial in this problem?
d. Carry out 15 trials, list your results, and compute an estimate of the probability that it takes the purchase of 10 or more boxes to get all six parts.
Answer:
a. Answers will vary; since there are six parts in a complete set, the ideal device to use in this problem is a number cube. Each number represents a different part.
b. Students are asked to estimate the probability that it takes 10 or more boxes to get all six parts, so it is necessary to look at the outcomes of the first 9 boxes. One roll of the number cube represents one box of cereal. A trial could be a string of 9 digits 1–6, the results of rolling a number cube.
c. A success would then be looking at the 9 digits and seeing if at least one digit 1–6 is missing. For example, the string 251466645 would count as a success, since part 3 was not acquired, whereas 344551262 would be considered a failure because it took fewer than 10 boxes to get all six parts.
d. Students are asked to generate 15 such trials, count the number of successes in the 15 trials, and divide the number by 15. The result is the estimated probability that it takes 10 or more boxes to acquire all six parts.
Question 3.
Suppose that a type A blood donor is needed for a certain surgery. Carry out a simulation to answer the following question: If 40% of donors have type A blood, what is an estimate of the probability that it will take at least four donors to find one with type A blood?
a. How would you simulate a blood donor having or not having type A?
b. What constitutes a trial for this simulation?
c. What constitutes a success for this simulation?
d. Carry out 15 trials, list your results, and compute an estimate for the probability that it takes at least four donors to find one with type A blood.
Answer:
a. With 40% taken as the probability that a donor has type A blood, a random digit would be a good device to use. For example,1, 2, 3, 4 could represent type A blood, and 0, 5, 6, 7, 8, 9 could represent non-type A blood.
b. The problem asks for the probability that it will take four or more donors to find one with type A blood. That implies that the first three donors do not have type A blood. So, a trial is three random digits.
c. A success is none of the three digits are 1, 2, 3, or 4. For example, 605 would be a success, since none of the donors had type A blood. An example of a failure would be 662.
d. Students are to generate 15 such trials, count the number of successes, and divide by 15 to calculate their estimated probability of needing four or more donors to get one with type A blood.
Eureka Math Grade 7 Module 5 Lesson 12 Problem Set Answer Key
Question 1.
Liang wants to form a chess club. His principal says that he can do that if Liang can find six players, including himself. How would you conduct a simulated model that estimates the probability that Liang will find at least five other players to join the club if he asks eight players who have a 70% chance of agreeing to join the club? Suggest a simulation model for Liang by describing how you would do the following parts.
a. Specify the device you want to use to simulate one person being asked.
b. What outcome(s) of the device would represent the person agreeing to be a member?
c. What constitutes a trial using your device in this problem?
d. What constitutes a success using your device in this problem?
e. Based on 50 trials, using the method you have suggested, how would you calculate the estimate for the probability that Liang will be able to form a chess club?
Answer:
a. Answers will vary. Using single digits in a random number table would probably be the quickest and most efficient device. 1–7 could represent “yes,” and 0, 8, 9 could represent “no.”
b. Answers will vary based on the device from part (a).
c. Using a random number table, a trial would consist of eight random digits.
d. Answers will vary; based on the above, a success is at least five people agreeing to join and would be represented by any set of digits with at least five of the digits being 1–7. Note that the random string 33047816 would represent 6 of 8 people agreeing to be a member, which is a success. The string 48891437 would represent a failure.
e. Based on 50 such trials, the estimated probability that Liang will be able to form a chess club would be the number of successes divided by 50.